全栈技术问题
1.详细解释JVM内存模型(堆、栈、方法区等),并说明垃圾回收机制在高并发场景下的优化思路。
- JVM内存模型:
- 堆(Heap):存放对象实例,是所有线程共享的,分为新生代(Eden、Survivor区)和老年代。
- 栈(Stack):线程私有,存放局部变量、方法调用栈帧。
- 方法区(Metaspace/JDK8+):存储类信息、常量池、静态变量等。
- 程序计数器(PC Register):记录当前线程执行到的字节码行号。
- 本地方法栈(Native Method Stack):执行Native方法(如JNI调用)。
- 高并发下的GC优化:
- 选择合适的垃圾回收器:如G1或ZGC,减少STW(Stop-The-World)时间。
- 调整堆大小:避免频繁Full GC,如-Xms和-Xmx设为相同值,减少动态扩展的开销。
- 优化对象分配:减少大对象直接进入老年代,合理设置-XX:MaxTenuringThreshold。
- 避免内存泄漏:如使用WeakHashMap管理缓存,防止长生命周期对象持有短生命周期对象的引用。
2.举例说明什么情况下会触发OutOfMemoryError,如何通过工具(如MAT)分析内存泄漏?
- OOM触发场景:
- 堆内存不足:java.lang.OutOfMemoryError: Java heap space(对象过多或内存泄漏)。
- 方法区溢出:java.lang.OutOfMemoryError: Metaspace(动态加载大量类)。
- 栈溢出:java.lang.StackOverflowError(递归调用过深)。
- MAT(Memory Analyzer Tool)分析步骤:
a.使用jmap -dump:format=b,file=heap.hprof < pid >导出堆内存快照。
b.用MAT打开.hprof文件,分析Dominator Tree,查看占用内存最多的对象。
c.检查Leak Suspects报告,定位可能的泄漏点(如未关闭的连接、静态集合类)。
3.使用过vue哪些功能?
(1)组件化开发:通过 Vue 的组件系统,将审核模块(如印章审核、工单审核)拆分为可复用的组件,提升代码维护性。
(2)数据绑定与响应式系统:利用 v-model 实现表单输入的双向绑定,并结合 Vue 的响应式特性实时更新界面状态。
(3)指令应用:
- v-for:渲染待审核的工单或印章列表
- v-if / v-show:根据权限或审核状态动态显示界面元素
(4)ElementUI 组件库:集成 ElementUI 的表格(el-table)、表单(el-form)、弹窗(el-dialog)等组件,快速构建用户界面。
(5)前端路由:通过 Vue Router 实现页面跳转(如从列表页跳转至详情页)。
(6)API 通信:使用 axios 或 fetch 调用后端 Spring Boot 接口,完成审核数据的提交与查询。
(7)事件处理:通过 @click 等事件监听用户操作(如审核通过、拒绝按钮点击)。
(8)状态管理:可能结合 Vuex 管理全局状态(如用户权限、审核流程状态)。
4.MyBatis 和 MyBatis-Plus 的主要区别?
(1)定位与功能
- MyBatis
- 核心功能:一个轻量级的 Java 持久层框架,专注于 SQL 与 Java 对象的映射(ORM),开发者需手动编写 SQL 和 DAO 层代码。
- 特点:灵活性强,适合需要精细化控制 SQL 的场景,但对基础 CRUD 操作需要重复编码。
- MyBatis-Plus
- 核心功能:基于 MyBatis 的增强工具,在保留 MyBatis 所有特性的基础上,提供了大量开箱即用的功能,大幅简化开发。
- 特点:内置通用 Mapper、代码生成器、分页插件、条件构造器等,显著减少重复代码。
(2)核心特性对比
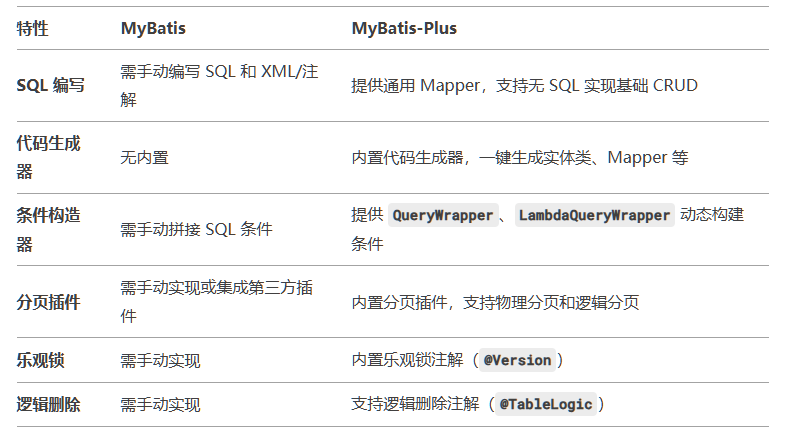
(3)开发效率
- MyBatis:适合对 SQL 有高度定制化需求的场景,但需要开发者自行处理大量模板代码(如 CRUD 操作)。
- MyBatis-Plus:通过自动化工具和增强功能,减少 80% 的基础代码量,尤其适合快速开发标准化业务。
(4)实际应用场景
- 选择 MyBatis:
- 需要完全控制 SQL 逻辑(如复杂查询、存储过程调用)。
- 项目对第三方依赖敏感,希望保持轻量化。
- 选择 MyBatis-Plus:
- 需要快速实现基础 CRUD 功能(如后台管理系统)。
- 希望减少重复代码,提升开发效率。
5.能否举例说明synchronized和ReentrantLock的区别?
- 实现机制:synchronized是JVM层面的关键字,依赖内置锁(Monitor),而ReentrantLock是API层面的锁,基于AQS(AbstractQueuedSynchronizer)。
- 功能扩展:ReentrantLock支持公平锁、可中断锁、超时锁等特性,synchronized仅支持非公平锁。
- 示例场景:在需要尝试获取锁或避免死锁时,使用ReentrantLock更灵活。例如,在分布式任务调度中,结合tryLock()实现超时等待。
6.如何判断一个SQL是否需要添加索引?
- 慢查询分析:通过EXPLAIN分析执行计划,观察type字段是否为ALL(全表扫描),或rows值是否过大。
- 高频查询字段:对WHERE、JOIN、ORDER BY子句中的高频字段添加索引。
- 覆盖索引:若查询仅需索引字段,可避免回表。
7.如何解决缓存穿透问题?
- 空值缓存:对查询结果为空的Key也进行缓存(设置较短过期时间),避免频繁查询数据库。
- 布隆过滤器:在查询前通过布隆过滤器判断Key是否存在,拦截无效请求。
8.什么是缓存穿透、击穿、雪崩以及解决方案。
(1) 缓存穿透(Cache Penetration)
- 定义:查询一个数据库中不存在的数据,导致请求直接打到数据库,缓存失去作用。
- 原因:恶意请求或非法查询。
- 解决方案:
- 布隆过滤器(Bloom Filter):在缓存层前加布隆过滤器,过滤掉不存在的数据。
- 缓存空值:即使查询结果为空,也将空结果缓存,设置较短的过期时间。
(2) 缓存击穿(Cache Breakdown)
- 定义:某个热点数据在缓存中过期,同时有大量请求访问该数据,导致请求直接打到数据库。
- 原因:热点数据集中过期。
- 解决方案:
- 设置热点数据永不过期:对热点数据不设置过期时间,或通过异步任务定期更新。
- 互斥锁(Mutex Lock):当缓存失效时,只允许一个线程去查询数据库并更新缓存,其他线程等待。
(3) 缓存雪崩(Cache Avalanche)
- 定义:大量缓存数据在同一时间过期,导致大量请求直接打到数据库,造成数据库压力激增。
- 原因:缓存集中过期或缓存服务宕机。
- 解决方案:
- 分散过期时间:为缓存数据设置随机的过期时间,避免集中过期。
- 多级缓存:使用多级缓存(如本地缓存 + Redis),减少对单一缓存的依赖。
- 高可用架构:通过 Redis 集群或哨兵模式保证缓存服务的高可用性。
9.Redis 数据类型
(1) String(字符串):
- 最基本的数据类型,可以存储文本、数字或二进制数据。
- 常用命令:SET, GET, INCR, DECR。
(2) Hash(哈希):
- 类似于字典,存储键值对集合,适合存储对象。
- 常用命令:HSET, HGET, HGETALL, HDEL。
(3) List(列表):
- 有序的字符串列表,支持从两端插入或删除元素。
- 常用命令:LPUSH, RPUSH, LPOP, RPOP, LRANGE。
(4) Set(集合):
- 无序且唯一的字符串集合,支持交集、并集等操作。
- 常用命令:SADD, SMEMBERS, SINTER, SUNION。
(5) Sorted Set(有序集合):
- 类似于 Set,但每个元素关联一个分数,用于排序。
- 常用命令:ZADD, ZRANGE, ZSCORE, ZREM。
(6) Bitmaps(位图):
- 通过位操作存储布尔值,适合存储标志位或进行位运算。
- 常用命令:SETBIT, GETBIT, BITCOUNT。
(7) HyperLogLog:
- 用于基数统计,适合估算集合中唯一元素的数量。
- 常用命令:PFADD, PFCOUNT, PFMERGE。
(8) Geospatial(地理空间):
- 存储地理位置信息,支持计算距离、范围查询等操作。
- 常用命令:GEOADD, GEODIST, GEORADIUS。
10. 熟悉哪些设计模式?请举例说明在项目中如何使用设计模式。
- 我熟悉常用的设计模式,如单例模式、工厂模式、观察者模式等。
- 在一个项目中,我使用了单例模式来确保数据库连接池的唯一性,避免重复创建连接。此外,我还使用了工厂模式来创建不同类型的支付对象(如支付宝、微信支付),通过工厂类来统一管理支付对象的创建。
11. 你如何使用Git进行版本控制?请描述你在团队协作中的Git工作流程。
- 我通常使用Git进行代码版本管理,常用的命令包括git clone、git pull、git commit、git push等。
- 在团队协作中,我们采用Git Flow工作流。每个新功能或修复都会从develop分支创建一个新的特性分支,开发完成后通过Pull Request合并回develop分支。发布时,我们会从develop分支创建release分支,经过测试后再合并到master分支。
12. 你如何优化MySQL查询性能?请举例说明你在项目中如何进行数据库优化。
- 我通常通过以下几种方式优化MySQL查询性能:
i.使用索引:为常用的查询字段创建索引,避免全表扫描。
ii.优化SQL语句:避免使用SELECT *,只查询需要的字段;避免使用子查询和不必要的JOIN。
iii.分库分表:对于大数据量的表,采用分库分表策略。 - 在一个电商项目中,我通过为订单表的user_id和order_date字段创建复合索引,显著提升了查询性能。
13. 你如何使用Redis?请举例说明你在项目中如何使用Redis解决实际问题。
- Redis是一个高性能的键值存储系统,常用于缓存、会话管理和消息队列等场景。
- 在一个高并发的电商项目中,我使用Redis缓存商品详情信息,减少数据库的查询压力。当用户请求商品详情时,首先从Redis中获取数据,如果缓存中没有,再从数据库中查询并写入Redis。
14. 你熟悉Spring Cloud吗?请举例说明你在微服务架构中如何使用Spring Cloud。
- 我熟悉Spring Cloud,它是一套用于构建微服务架构的工具集,包括服务发现(Eureka)、配置管理(Config)、负载均衡(Ribbon)等。
- 在一个微服务项目中,我使用Eureka作为服务注册中心,各个微服务在启动时向Eureka注册,服务之间通过Ribbon进行负载均衡调用。此外,我还使用Spring Cloud Config来集中管理各个微服务的配置。
15. 你如何理解前端框架Vue?请举例说明你在项目中如何使用Vue。
- Vue是一个渐进式JavaScript框架,用于构建用户界面。它采用组件化开发模式,数据驱动视图更新。
- 在一个后台管理系统中,我使用Vue构建了前端页面。通过Vue的组件化开发,我将页面拆分为多个可复用的组件,如导航栏、表格、表单等。同时,我使用Vuex进行状态管理,确保各个组件之间的数据共享和同步。
16.面向对象编程(OOP)的三大特性是:
(1) 封装(Encapsulation):
- 将数据和操作数据的方法绑定,隐藏内部实现,仅通过接口与外界交互。
- 优点:提高代码安全性,便于维护和复用。
(2) 继承(Inheritance):
- 子类继承父类的属性和方法,并可扩展或重写。
- 优点:减少代码重复,增强可扩展性。
(3) 多态(Polymorphism):
- 同一操作在不同对象上有不同表现,通常通过方法重写和接口实现。
- 优点:提高代码灵活性和可扩展性。
17.单例模式实现方式:
(1) 懒汉式(Lazy Initialization):在第一次调用时创建实例。
- 优点:延迟加载,节省资源。
- 缺点:非线程安全,多线程环境下可能创建多个实例。
(2) 饿汉式(Eager Initialization):在类加载时创建实例。
- 优点:线程安全,实现简单。
- 缺点:类加载时就创建实例,可能浪费资源。
(3) 静态内部类(Static Inner Class):利用类加载机制保证线程安全,同时实现延迟加载。
- 优点:线程安全,延迟加载,实现简单。
- 缺点:无法传递参数初始化实例。
18.MySQL索引
(1)按数据结构分类
- B+Tree 索引:
- MySQL 默认的索引类型,适用于全键值、键值范围和键值前缀查询。
- 支持 =、>、<、BETWEEN、IN 等操作。
- Hash 索引:
- 基于哈希表实现,适用于等值查询(=),不支持范围查询。
- 内存存储引擎(如 MEMORY)支持 Hash 索引。
- 全文索引(FULLTEXT):
- 用于全文搜索,适用于 MATCH AGAINST 操作。
- 仅支持 InnoDB 和 MyISAM 存储引擎。
- 空间索引(R-Tree):
- 用于地理空间数据,支持几何数据类型。
(2)按功能分类
- 用于地理空间数据,支持几何数据类型。
- 普通索引(INDEX):
- 最基本的索引,没有任何约束。
- 唯一索引(UNIQUE INDEX):
- 确保索引列的值唯一,允许有空值。
- 主键索引(PRIMARY KEY):
- 特殊的唯一索引,不允许有空值,每个表只能有一个主键。
- 组合索引(复合索引):
- 对多个列联合创建的索引,遵循最左前缀原则。
- 前缀索引:
- 对列的前缀部分创建索引,节省存储空间。
19.MySQL表常见连接方式
(1) LEFT JOIN(左连接)
- 定义:以左表(LEFT JOIN 左侧的表)为基准,返回左表的所有行,即使右表中没有匹配的行。
- 结果:
- 如果右表有匹配的行,则返回匹配的数据。
- 如果右表没有匹配的行,则右表的列返回NULL。
(2) RIGHT JOIN(右连接)
- 定义:以右表(RIGHT JOIN 右侧的表)为基准,返回右表的所有行,即使左表中没有匹配的行。
- 结果:
- 如果左表有匹配的行,则返回匹配的数据。
- 如果左表没有匹配的行,则左表的列返回 NULL。
(3) INNER JOIN(内连接)
- 定义:返回两个表中匹配的行。如果某一行在其中一个表中没有匹配,则不会返回该行。
(4) FULL OUTER JOIN(全外连接)
- 定义:返回两个表中所有行,无论是否匹配。如果某一行在其中一个表中没有匹配,则缺失的部分用 NULL 填充。